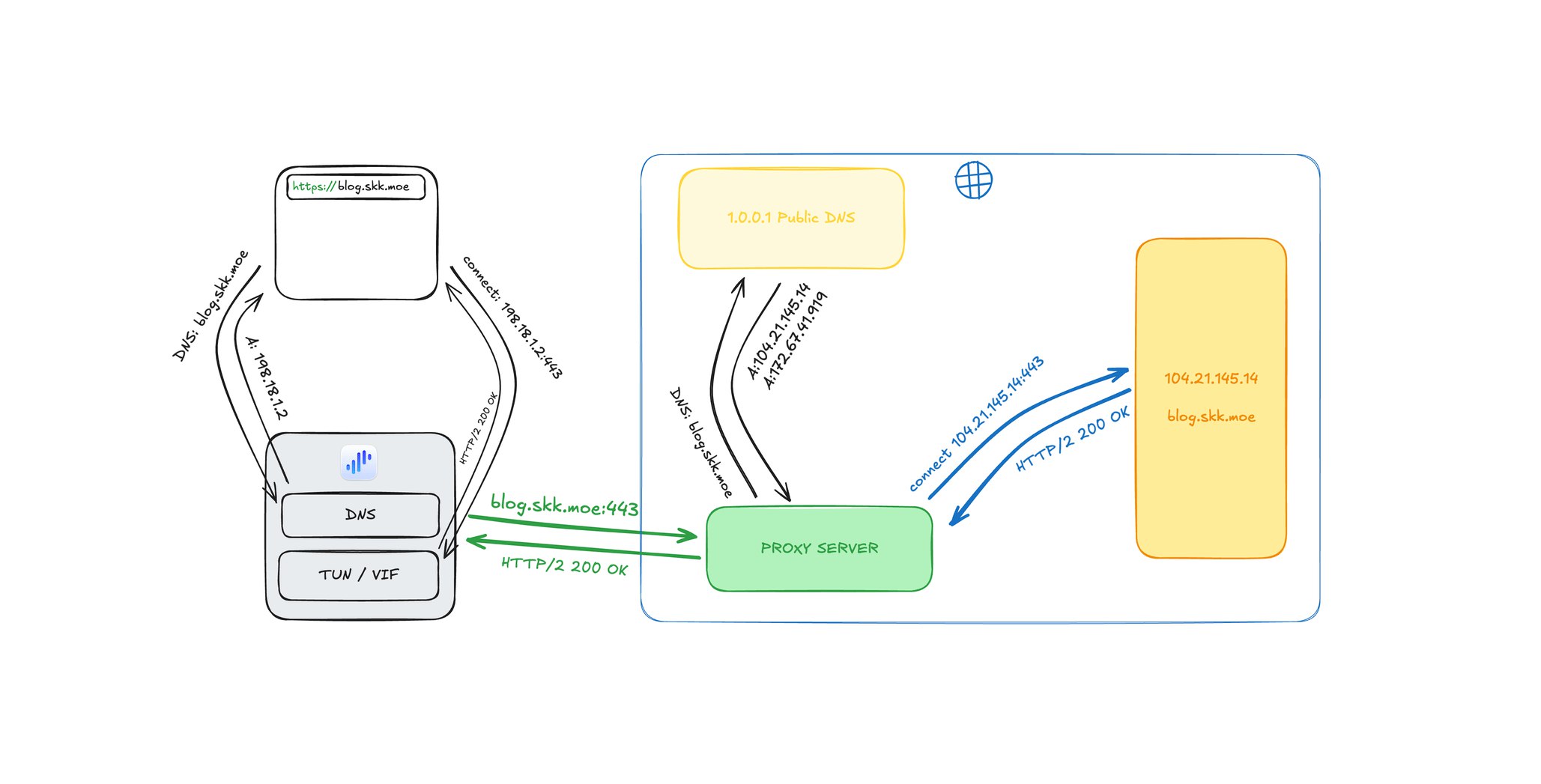
深度解析Fake IP与Real IP:网络分流的最佳实践2001 年 4 月 IETF 通过的 RFC 3089中描述的 Fake IP,是四层代理分流场景下性能相对最佳、体验相对最好、实现相对最简单的「最佳实践」。相比之下,Real IP模式为了接近其性能,需要付出大量的额外配置代价。
1. 拆解「DNS 泄漏」的迷思在许多三层 VPN 提供商(如 ExpressVPN, NordVPN)及 KOL 的宣传下,「DNS 泄漏」被渲染成洪水猛兽。但要理解它,首先要理解 DNS 解析的参与者:
发起查询的用户
递归 DNS(Local DNS):如运营商 DNS、公共 DNS(1.1.1.1 等)。
权威 DNS(Authoritative DNS):最终决定域名指向的服务器。
DNS 泄漏的原理「DNS 泄漏」本质上查询的是 递归 DNS 请求权威 DNS 时所使用的出口 IP。
查询工具通过让用户请求完全随机的域名(绕开缓存),迫使递归 DNS 请求权威 DNS,从而记录下递归 DNS 的出口 IP。
为什么 DNS 泄漏不值得恐慌?
地理位置难以关联:Cloudfl ...
1 介绍在分布式系统中,很重要的一个能力就是消息中间件。我们通过消息队列实现 功能解耦、消息有序性、消息路由、异步处理、流量削峰 等能力。目前主流的Mq主要有 RabbitMQ 、RocketMQ、kafka,可以参考这篇《MQ系列2:消息中间件的技术选型 | 数根朽木,》。除了这些主流MQ之外,Redis也具备实现消息队列的能力。这一篇记录一下消息队列主要实现哪些能力,原理是什么,以及如何在 Redission 中应用。
2 关于消息队列2.1 什么是消息队列消息中间件是指在分布式系统中完成消息的发送和接收的基础软件。消息中间件也可以称消息队列(Message Queue / MQ),用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息队列模型,可以在分布式环境下扩展进程的通信。简而言之,互联网场景中经常使用消息中间件进行消息路由、订阅发布、异步处理等操作,来缓解系统的压力。
Broker: 消息服务器,作为Server提供消息核心服务,一般会包含多个Q。
Producer: 消息生产者,业务的发起方,负责生产消 ...
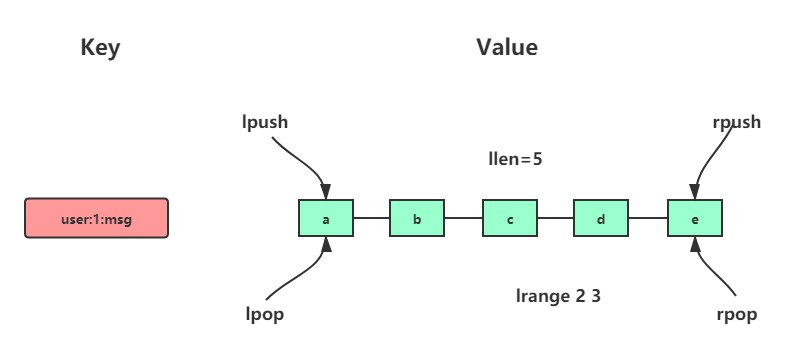
1 先导我们在《Redis系列:使用List实现消息队列 | 数根朽木,》这一篇中详细讨论了如何使用List实现消息队列,但同时也看到很多局限性,比如:
不支持消息确认机制,没有很好的ACK应答
不支持消息回溯,无法排查问题和做消息分析
List按照FIFO机制执行,所以存在消息堆积的风险。
查询效率低,作为线性结构,List中定位一个数据需要进行遍历,O(N)的时间复杂度
不存在消费组(Consumer Group)的概念,无法实现多个消费者组成分组进行消费
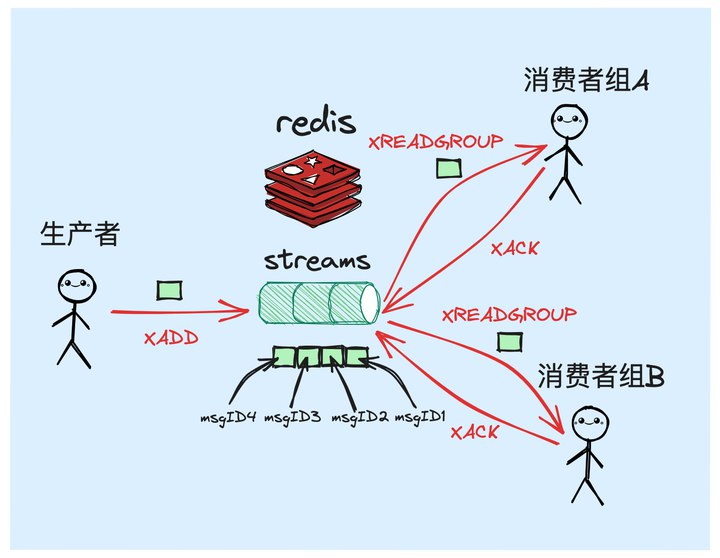
2 关于StreamRedis Stream是Redis 5.0版本中引入的一种新的数据结构,它主要用于高效地处理流式数据,特别适用于消息队列、日志记录和实时数据分析等场景。以下是对Redis Stream的 主要特征:
1. 数据结构:Redis Stream是一个由有序消息组成的日志数据结构,每个消息都有一个全局唯一的ID,确保消息的顺序性和可追踪性。
2. 消息ID:消息的ID由两部分组成,分别是毫秒级时间戳和序列号。这种设计确保了消息ID的单调递增性,即新消息的ID总是大于旧消息的ID。
3. 消费者组:Redis ...
Redis
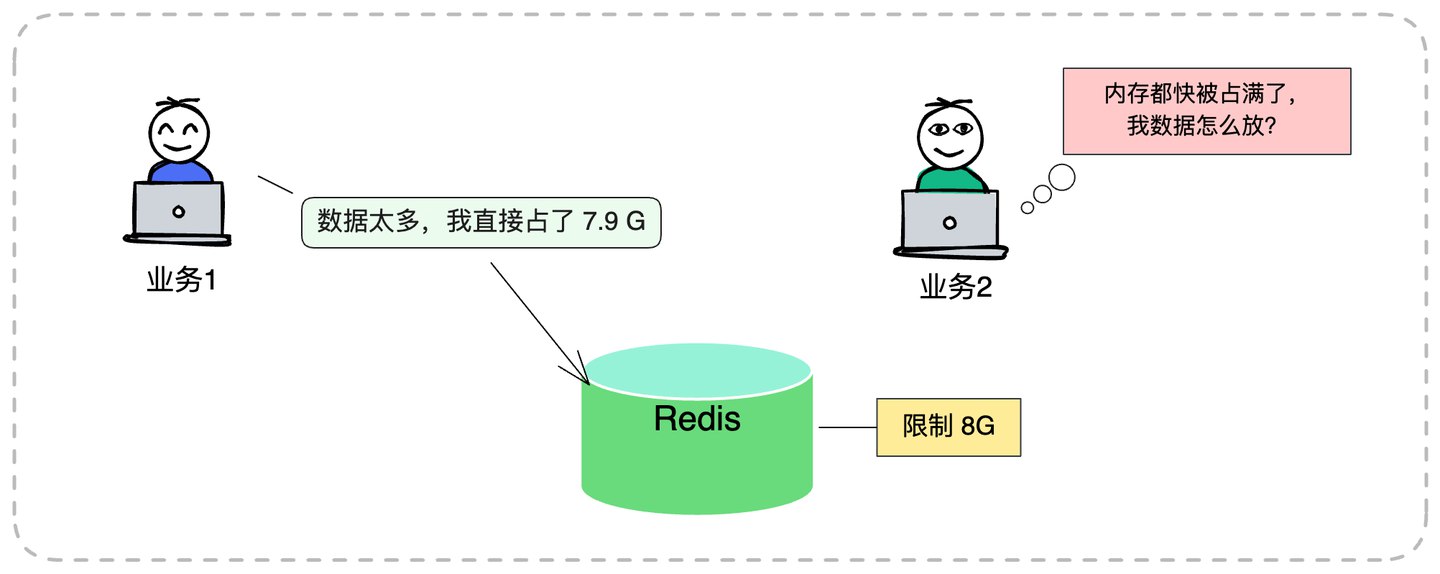
未读1 前言通过前面的一些文章我们知道,Redis的各项能力是基于内存实现的,相对其他的持久化存储(如MySQL、File等,数据持久化在磁盘上),性能会高很多,这也是高速缓存的一个优势。
但是问题来了,每一台机器内存终归是有限的,即使是集群模式,总的内存空间也是有限的,不能无限制的消耗。而在Redis的使用过程中,很有可能出现使用消耗超过内存实际大小的情况。比如以下几种情况:
未设置过期时间,Redis的Key将一直存在,直至我们明确将它删除。
过度跟不合理的持久化(无论是RDB快照 或是 AOF日志),都会在内存和磁盘中反复操作,需要一定的内存空间进行处理。
不及时清理过期缓存:清理过期缓存的方式主要有以下两种,并不是实时或者准实时,所以存在部分过期缓存依旧存在的问题。
主动定期删除: Redis 默认每 1 秒运行 10 次(平均每 100 ms 执行一次),每次随机抽取部分设置过期时间的 key,检查是否过期,若是过期就直接删除,直至过期的 key 比率低于 1/4。
被动惰性删除:缓存过期并不马上清理,当客户端的请求查询该 key 的时候,检查下 key 是否过期,如 ...
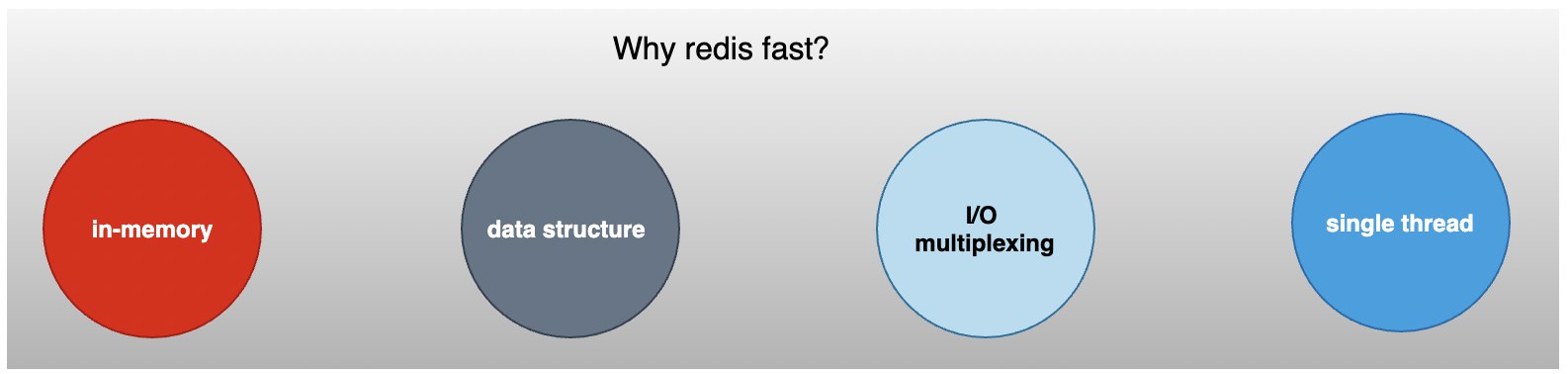
1 背景分布式系统绕不开的核心之一的就是数据缓存,有了缓存的支撑,系统的整体吞吐量会有很大的提升。通过使用缓存,我们把频繁查询的数据由磁盘调度到缓存中,保证数据的高效率读写。当然,除了在内存内运行还远远不够,我们今天就以具有代表性的缓存中间件Redis为例子,分析下,它是如何达到飞起的效率。
2 Redis高效性能分析Redis之所以能够提供超高的执行效率,主要从以下几个维度来实现的:
存储模式:基于内存实现,而非磁盘
数据结构:基于不同业务场景的高效数据结构
动态字符串(REDIS_STRING):整数(REDIS_ENCODING_INT)、字符串(REDIS_ENCODING_RAW)
双端列表(REDIS_ENCODING_LINKEDLIST)
压缩列表(REDIS_ENCODING_ZIPLIST)
跳跃表(REDIS_ENCODING_SKIPLIST)
哈希表(REDIS_HASH)
整数集合(REDIS_ENCODING_INTSET)
线程模型: Redis 的网络 IO 以及键值对指令读写是由单个线程来执行的,避免了不必要的contextswitch和竞选
...

调优排查
未读0x01 案例一事故时间:2018年6月13日
故障类型:java.lang.OutOfMemoryError: Java heap space
事故经过:某考务管理系统,前期收集考生报名信息时允许上传ZIP附件提交相关材料,后台服务会解析压缩包并从中获取相关文件。
系统运行后不久,考务群就陆续有人反馈报名网站打不开,无法访问等等。让运维重启系统后,又恢复正常,跑了一段时间以后,又有人说无法访问。仔细检查故障时的日志,发现故障时间点都是发生在有人上传ZIP文件的时候。
从服务器上提取了一部分样本,发现压缩文件里面包含若干个TXT文件,TXT文件中是重复的字符,类似AAA…该TXT文件原始数据巨大且单调重复,导致压缩后的ZIP却非常小,真是个天才!直觉告诉我们这是被恶意攻击了,遂暂时关闭了文件上传接口,改为通过表单录入信息报名。
事后复盘当时的代码,发现处理ZIP文件时没有释放到磁盘临时文件,都是在内存中直接解压并读取解压后的文本数据,这就给了攻击者可乘之机。但是后来专门去研究了下这方面的安全漏洞,发现这是一种ZIP炸弹(ZIP of Death or ZIP Bomb),即使是释放到磁 ...

前言
年前放假的几个月内,公司项目发生了两次事故,虽然与我无关,但事故发生后整个团队都受到影响,主管需要给客户写事故报告,客户甚至打电话给公司领导严肃批评,我想经历过这种事的朋友不在少数,但很多刚入行的朋友可能不太清楚其中利害,这里我分享出来希望对大家有所帮助。
事故经过
三个月内一共发生两次生产环境事故,一个是接口超时导致服务雪崩,一个是锁表导致核心功能停滞一小时。
1、接口超时事故1)现象2021年12月某周一上午,负责管理网络的同事(俗称网管)一大早巡检过程中发现有一个服务挂掉了,他当时没在意,直接重启就好了,但到了10点左右,忽然三四个服务:挂号服务、门诊服务、检查报告服务等一起挂掉了,而且重启十几分钟后又会挂掉,瞬间公司就炸锅了,网管、开发人员、技术主管集体冒汗,在紧急处理过程中,还不断有院方电话打给主管、总经理直到大老板,领导就站在我们背后着急的等待我们处理,我想很多人应该有画面了。
2原因大概到中午都没解决,因为没有日志平台的情况下,定位问题是一件不容易的事情,后来在中午休息时间技术主管和我们终于发现了门诊服务中调用某软his接口出现超时,而周一上午的流量又很大,平常 ...

Java核心
未读虚拟机篇1. JVM 内存结构要求
掌握 JVM 内存结构划分
尤其要知道方法区、永久代、元空间的关系
结合一段 java 代码的执行理解内存划分
执行 javac 命令编译源代码为字节码
执行 java 命令
创建 JVM,调用类加载子系统加载 class,将类的信息存入方法区
创建 main 线程,使用的内存区域是 JVM 虚拟机栈,开始执行 main 方法代码
如果遇到了未见过的类,会继续触发类加载过程,同样会存入方法区
需要创建对象,会使用堆内存来存储对象
不再使用的对象,会由垃圾回收器在内存不足时回收其内存
调用方法时,方法内的局部变量、方法参数所使用的是 JVM 虚拟机栈中的栈帧内存
调用方法时,先要到方法区获得到该方法的字节码指令,由解释器将字节码指令解释为机器码执行
调用方法时,会将要执行的指令行号读到程序计数器,这样当发生了线程切换,恢复时就可以从中断的位置继续
对于非 java 实现的方法调用,使用内存称为本地方法栈(见说明)
对于热点方法调用,或者频繁的循环代码,由 JIT 即时编译器将这些代码编译成机器码缓存,提高执行性能
说明
加粗字体代表了 ...

基础篇
基础篇要点:算法、数据结构、基础设计模式
1. 二分查找要求
能够用自己语言描述二分查找算法
能够手写二分查找代码
能够解答一些变化后的考法
算法描述
前提:有已排序数组 A(假设已经做好)
定义左边界 L、右边界 R,确定搜索范围,循环执行二分查找(3、4两步)
获取中间索引 M = Floor((L+R) /2)
中间索引的值 A[M] 与待搜索的值 T 进行比较
① A[M] == T 表示找到,返回中间索引
② A[M] > T,中间值右侧的其它元素都大于 T,无需比较,中间索引左边去找,M - 1 设置为右边界,重新查找
③ A[M] < T,中间值左侧的其它元素都小于 T,无需比较,中间索引右边去找, M + 1 设置为左边界,重新查找
当 L > R 时,表示没有找到,应结束循环
更形象的描述请参考:binary_search.html
算法实现
1234567891011121314public static int binarySearch(int[] a, int t) &# ...

Oracle 于 2014 发布了 Java8(jdk1.8),它较 jdk7 有很多变化或者说是优化,比如 interface 里可以有静态方法,并且可以有方法体,这一点就颠覆了之前的认知;java.util.HashMap 数据结构里增加了红黑树;还有众所周知的 Lambda 表达式等等。本文不能把所有的新特性都给大家一一分享,只列出比较常用的新特性给大家做详细讲解。更多相关内容请看官网关于 Java8 的新特性的介绍。
Interfaceinterface 的设计初衷是面向抽象,提高扩展性。这也留有一点遗憾,Interface 修改的时候,实现它的类也必须跟着改。
为了解决接口的修改与现有的实现不兼容的问题。新 interface 的方法可以用default 或 static修饰,这样就可以有方法体,实现类也不必重写此方法。
一个 interface 中可以有多个方法被它们修饰,这 2 个修饰符的区别主要也是普通方法和静态方法的区别。
default修饰的方法,是普通实例方法,可以用this调用,可以被子类继承、重写。
static修饰的方法,使用上和一般类静态方法一样。但 ...



