
前言
支付功能其实并没有想的那么难,除了微信支付宝提供了原生工具类,其他开源的工具也挺多,纯粹可以当成支付版的CRUD一样操作。以面试官的角度来提问一些支付相关的问题,并做出回答,让你对企业中支付的全貌有个大概的认知。
正文1、你知道直连模式和服务商模式吗
网上的课程一般给你演示的都是直连模式,而企业中有不少是申请成为了服务商,因为里面有佣金提成。
我粗俗地解释,直连模式,就是说你是一个会做生意的老板,自己会搞钱,搞到钱存到自己的一个商户号里。
服务商模式,就是说你是一个会做生意的老板,但是自己不搞钱只提供做生意的渠道,其他老板用你的渠道,搞到钱了让你洗一洗,你分别转到他们各自的商户号里去,而你收取一点点服务费。
然后我们对照上面的话再稍微专业点解释,直连模式就是你得自己接入支付功能,啥都要你自己做,服务商模式就是啥都不需要你做,你就提供个商户号,剩下的支付接入功能服务商给你全部搞定。
如果面试官问你这个问题,你只要意思稍微到了就行,别人就知道你是做过的。
2、服务商模式下,你们如何控制多个子商户结算和退款的
假如你有自己的一家公司,专门提供支付服务,而且申请成为了服务商,那么你就 ...
Spring 中的事务隔离级别和数据库中的事务隔离级别稍有不同,以 MySQL 为例,MySQL 的 InnoDB 引擎中的事务隔离级别有 4 种,而 Spring 中却包含了 5 种事务隔离级别。
1.什么是事务隔离级别?事务隔离级别是对事务 4 大特性中隔离性的具体体现,使用事务隔离级别可以控制并发事务在同时执行时的某种行为。
比如,有两个事务同时操作同一张表,此时有一个事务修改了这张表的数据,但尚未提交事务,那么在另一个事务中,要不要(或者说能不能)看到其他事务尚未提交的数据呢?
这个问题的答案就要看事务的隔离级别了,不同的事务隔离级别,对应的行为模式也是不一样的(有些隔离级别可以看到其他事务尚未提交的数据,有些事务隔离级别看不到其他事务尚未提交的数据),这就是事务隔离级别的作用。
2.Spring 事务隔离级别Sping 中的事务隔离级别有 5 种,它们分别是:
DEFAULT:Spring 中默认的事务隔离级别,以连接的数据库的事务隔离级别为准;
READ_UNCOMMITTED:读未提交,也叫未提交读,该隔离级别的事务可以看到其他事务中未提交的数据。该隔离级别因为可以 ...

MySQL
未读1 为什么需要数据库备份
灾难恢复:当发生数据灾难的时候,需要对损坏的数据进行恢复和还原
需求的变更或者回滚:当需求发生变更,或者需要回滚到之前的版本时,数据库备份也显得很重要。
审计:需要知道某一个阶段的数据或者Schema的实际情况
测试:将实际的生产环境的数据导入到本地备份为测试数据,来验证新功能,可以省去很多麻烦。
2 备份需要考虑的几个关键点
恢复点目标(PRO):可以容忍丢失多少数据
恢复时间目标(RTO):需要等待多久将数据恢复
恢复的时候是需要持续提供服务 还是 停机恢复。
需要恢复的内容:整个服务器,多库多表,单库单表,或是特定的事务或语句。
3 备份方案3.1 离线备份和在线备份离线备份:就是传统意义上的cold backup(冷备份):需要关闭MySQL服务,读写请求均不允许状态下进行,这种模式下数据损坏和不一致性风险最小。半离线备份:也就是我们说的warm backup(温备份): MySQL服务不关闭,但只开放了Read操作,关闭了Write操作。在线备份:也就是hot backup(热备份):在数据备份的同时,MySQL业务持续进行中,仅限于InnoDB ...
Redis
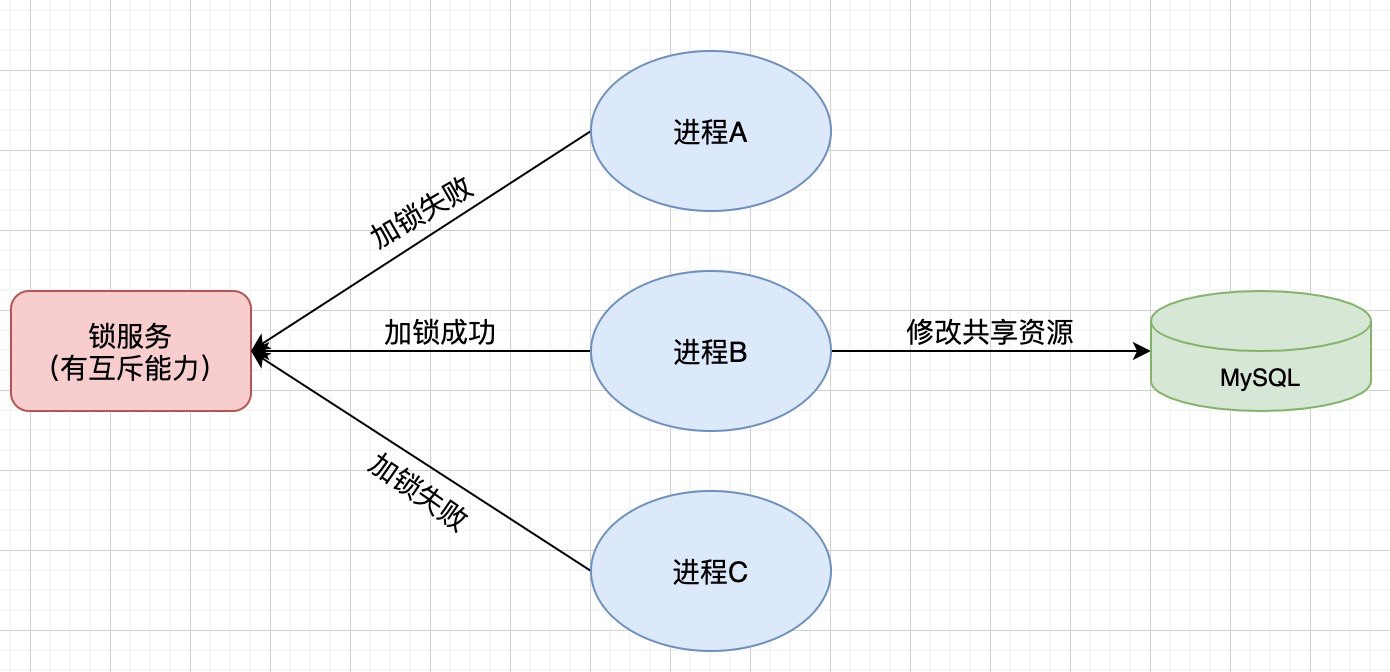
未读1 先来了解下分布式锁1.1 什么是分布式锁分布式锁,即分布式系统中的锁,我们通过锁解决 控制共享资源访问 的问题,来保证只有一个线程可以访问被保护的资源。
1.2 分布式锁的实现方案
基于数据库实现分布式锁
基于Zookeeper实现分布式锁
基于Redis实现分布式锁
等等,本篇基于Redis角度进行讨论
1.3 分布式锁满足哪些特性
互斥性:在分布式系统下,一个事件在同一个时间内只能被一个线程执行,即只能有一个线程持有锁。
安全性:可以方便的获取锁和释放锁,不产生死锁情况
过期性:具备锁失效机制,即可以在时效预期外自动解锁,防止死锁
可重入:具备可重入特性(可理解为重新进入,由多于一个任务并
高性能:高性能的获取锁与释放锁
高可用性:高可用的获取锁与释放锁
1.4 互斥特性1.4.1 实现互斥特性1.4.1.1 SETNX命令SETNX 是 set if not exists 的缩写,当且仅当 key 不存在时,则设置 value 给这个key。若给定的 key 已经存在,则 SETNX 不做任何动作。命令的返回值说明:
1:说明该进程获得锁,将 key 的值设为 valu ...
Redis
未读1 介绍通过前面的章节,我们知道,Redis 是一个kv型数据库,我们所有的数据都是存放在内存中的,但是内存是有大小限制的,不可能无限制的增量。
想要把不需要的数据清理掉,一种办法是直接删除,这个咱们前面章节有详细说过;另外一种就是设置过期时间,缓存过期后,由Redis系统自行删除。
这边需要注意的是,缓存过期之后,并不是马上删除的,那Redis是怎么删除过期数据的呢?主要通过两个方式
惰性删除
通过定时任务,定期选取部分数据删除
2 Redis缓存过期命令我们通过以下指令给指定key的缓存设置过期时间,如果都没设置过期时间, key 将一直存在,直到我们使用 Del 的命令明确删除掉。
12# 缓存时间过期命令,参考如下EXPIRE key seconds [ NX | XX | GT | LT]
Redis 7.0 开始,EXPIRE 添加了 NX、XX和GT、LT 选项,分别代表如下:
NX:仅当Key没有过期时设置过期时间
XX:仅当Key已过期时设置过期时间
GT:仅当新到期时间大于当前到期时间时设置到期时间
LT:仅当新到期时间小于当前到期时间时设置到期时间
其 ...
MySQL
未读1 为什么要分库分表物理服务机的CPU、内存、存储设备、连接数等资源有限,某个时段大量连接同时执行操作,会导致数据库在处理上遇到性能瓶颈。为了解决这个问题,行业先驱门充分发扬了分而治之的思想,对大库表进行分割,
然后实施更好的控制和管理,同时使用多台机器的CPU、内存、存储,提供更好的性能。而分治有两种实现方式:垂直拆分和水平拆分。
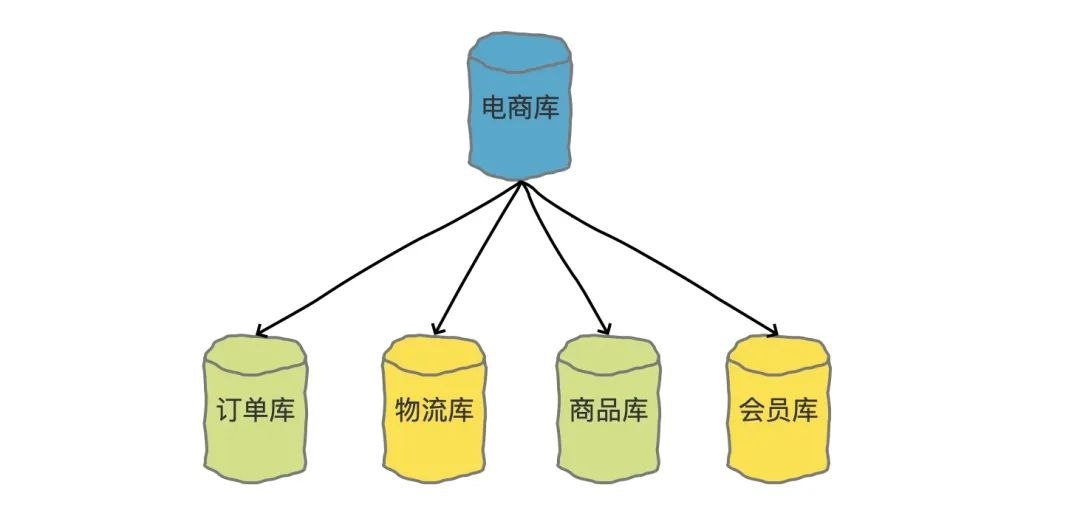
2 垂直拆分(Scale Up 纵向扩展)垂直拆分分为垂直分库和垂直分表,主要按功能模块拆分,以解决各个库或者各个表之间的资源竞争。比如分为订单库、商品库、用户库…这种方式,多个数据库之间的表结构是不同的。
2.1 垂直分库先说说垂直分库。垂直分库其实是一种简单逻辑分割。比如我们的数据库中有商品表Products、还有对订单表Orders,还有积分表Scores。接下来我们就可以创建三个数据库,一个数据库存放商品,一个数据库存放订单,一个数据库存放积分。
垂直分库有一个优点,他能够根据业务场景进行孵化,比如某一单一场景只用到某2-3张表,基本上应用和数据库可以拆分出来做成相应的服务。拆分方式如下图所示:
2.2 垂直分表再来说说垂直分表,比较适用于那种字 ...
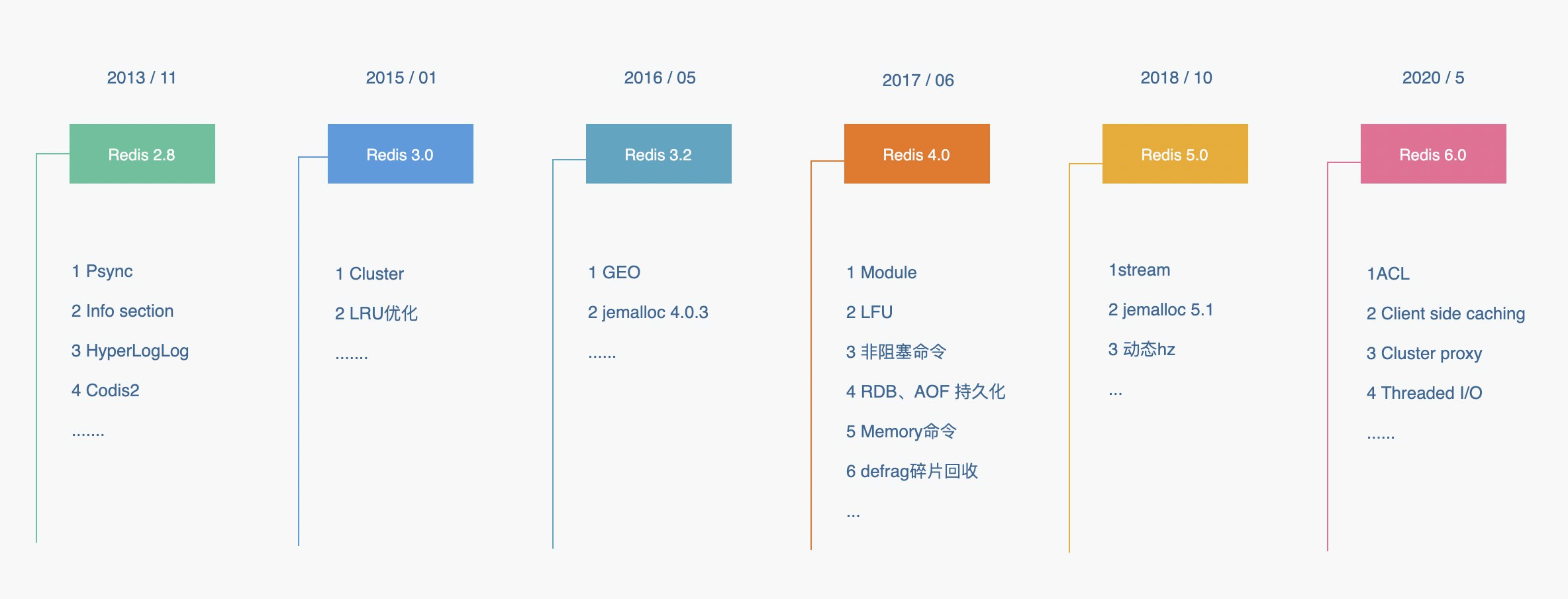
架构与思维
未读背景2020年5月份,Redis官方推出了令人瞩目的 Redis 6.0,提出很多新特性,包括了客户端缓存 (Client side caching)、ACL、Threaded I/O 和 Redis Cluster Proxy 等诸多新特性。如下: 我们也专门对 Redis 6.0的 Threaded I/O(多线程网络I/O 模式)做了很详细的说明,有兴趣的翻到前面一篇。这一篇咱们就来聊下这个Client side caching(客户端缓存),看看Redis为什么需要客户端缓存、是基于什么原理实现的,以及具体应该怎么使用。
1 为什么需要客户端缓存1.1 缓存服务的目的回顾一下我们 在第一篇 《Redis系列1:深刻理解高性能Redis的本质 | 数根朽木,)》中说过的,Redis的读写操作都是在内存中实现了,相对其他的持久化存储(如MySQL、File等,数据持久化在磁盘上),性能会高很多。因为我们在操作数据的时候,需要通过 IO 操作先将数据读取到内存里,增加工作成本。上面那张图来源于网络,可以看看他的金字塔模型,越往上执行效率越高,价格也就越 ...
1 介绍在之前的一篇文章《架构与思维-一次雪崩的灾难复盘-转载 | 数根朽木,》中,我们比较清晰的描述了缓存雪崩、穿透、击穿的各自特征和解决方案,想详细了解的可以移步。
最近在配合HR筛选候选人,作为大厂的业务方向负责人,招人主要也是我们自己团队在用,而缓存是必不可少的面试选项之一。下面我们就来聊一聊在特定业务场景下缓存击穿和雪崩的应对场景!
2 问题背景
一个核心的应用或者服务(比如微信、钉钉、百度APP),高峰QPS是百万甚至是千万
★ 分析:上述类型的应用具有很明显的峰值 高斯分布的特征,就是9~10点是用户早高峰。微信是,百度APP是,钉钉也是,钉钉一般给政企、教学等使用,通用是10点左右峰值期,每天的峰值如下:
应用缓存了用户的基本信息,如(姓名、性别、职业、地址等),假设以为用户Id为Cache的key,那每个用户都有一个基础信息的缓存。
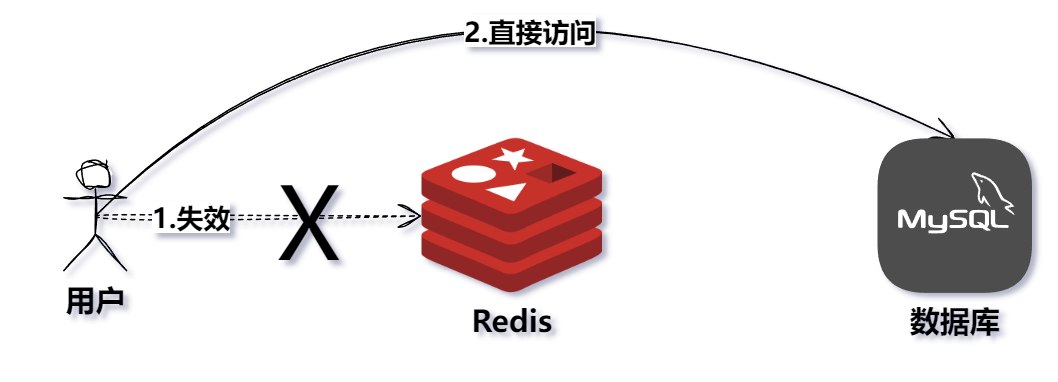
因为不知名的原因,导致缓存都丢了(可能是缓存集体过期、故障导致缓存失效、程序bug导致缓存误删、服务器重启导致内存清理)。
恰巧是访问高峰期(比如9点早高峰),千百万的请求狂奔而来,查不到缓存,透过缓存层直接投入数据库。
基于 ...
1 真实案例云办公系统用户实时信息查询功能优化发布之后,系统发生宕机事件(系统挂起,页面无法加载)。
1.1 背景我们IM原有的一个功能,当鼠标移动到用户头像的时候,会显示出用户的基本信息。信息比较简单,只包含简单的用户名、昵称、性别、邮箱、电话等基本数据,
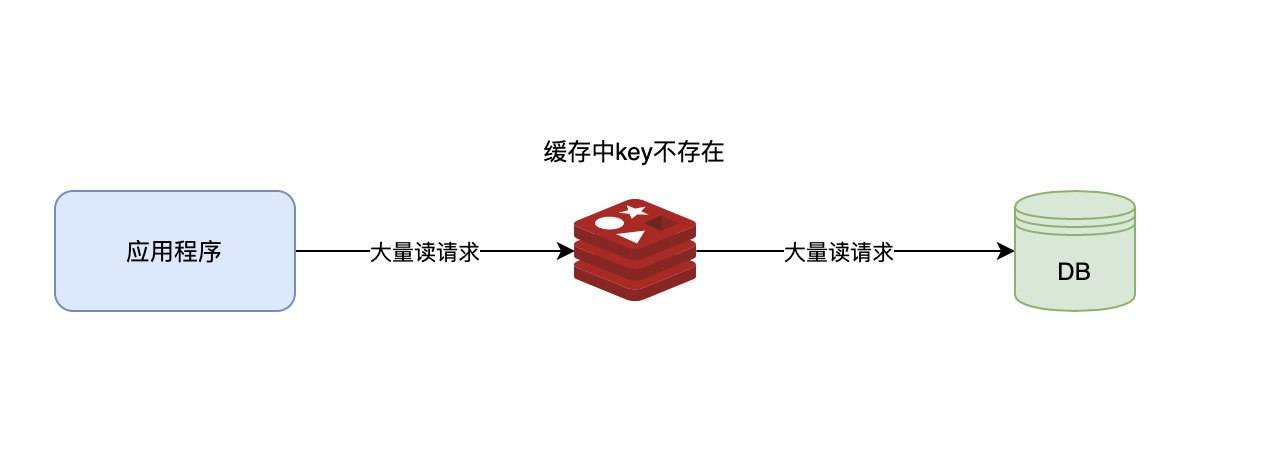
这是一个典型的数据查询,大概过程如下左侧,访问用户基本信息的时候会先去Redis中查一下,如果不存在,就把大约2W左右的用户数据一次性取出来,保存在Redis中,因为用户基本信息在同一张表上,用户信息表的数据量也很少,所以一直也没什么问题。
过程如下图左侧所示。
后续对功能做了优化,原有采集的信息除了用户的基本信息之外,还采集了教育经历、工作经历、所获勋章等。
这些信息存储在不同的表里面,所以采集过程是一个复杂的联表查询,特别是有些基础表数据量比较大,执行效率也是比较慢的。
如果把所有用户全部取出来并存储在一个Redis节点中,明显已经不适用,一个是批量查询导致数据库执行效率慢,一个是Redis单节点数据太大。
所以开发同学做了下优化,每次只取单个用户的综合信息存在Redis中,一个用户建一个缓存,如上图右侧所示。
1.2 ...
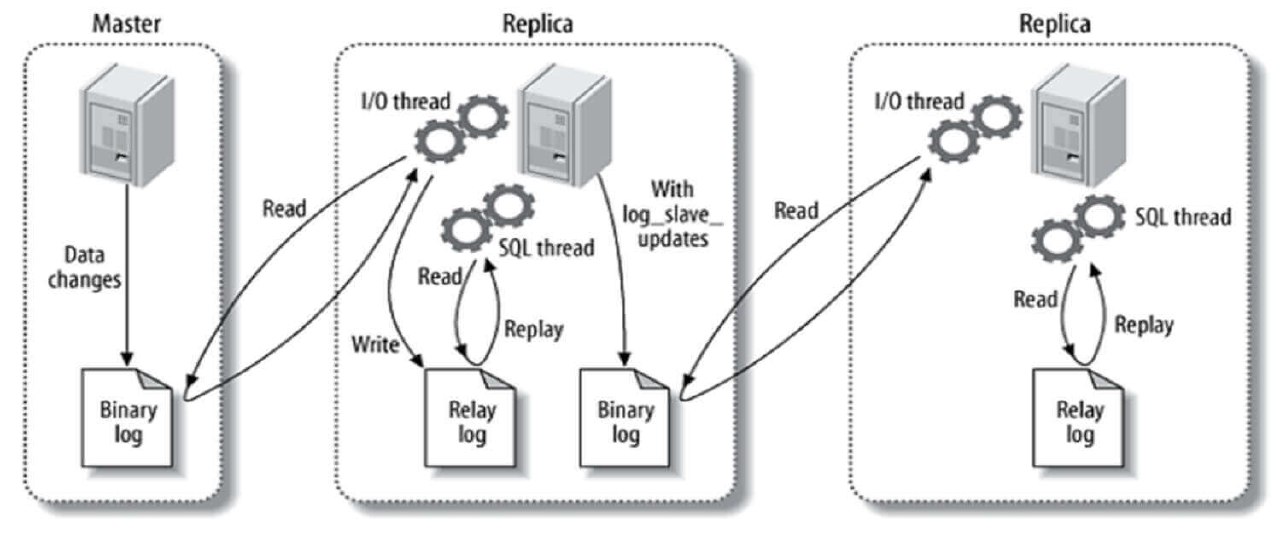
MySQL
未读概念主从复制,是指建立一个和主数据库完全一样的数据库环境(称为从数据库),并将主库的操作行为进行复制的过程:将主数据库的DDL和DML的操作日志同步到从数据库上,
然后在从数据库上对这些日志进行重新执行,来保证从数据库和主数据库的数据的一致性。
为什么要做主从复制1、在复杂的业务操作中,经常会有操作导致锁行甚至锁表的情况,如果读写不解耦,会很影响运行中的业务,使用主从复制,让主库负责写,从库负责读。
即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运行。
2、保证数据的热备份,主库宕机后能够及时替换主库,保障业务可用性。
3、架构的演进:业务量扩大,I/O访问频率增高,单机无法满足,主从复制可以做多库方案,降低磁盘I/O访问的频率,提高单机的I/O性能。
4、本质上也是分治理念,主从复制、读写分离即是压力分拆的过程。
5、读写比也影响整个拆分方式,读写比越高,主从库比例应越高,才能保证读写的均衡,才能保证较好的运行性能。读写比下的主从分配方法下:
读写比
主库
从库
50:50
1
1
66.6:33.3
1
2
80:20
1 ...



