Java核心
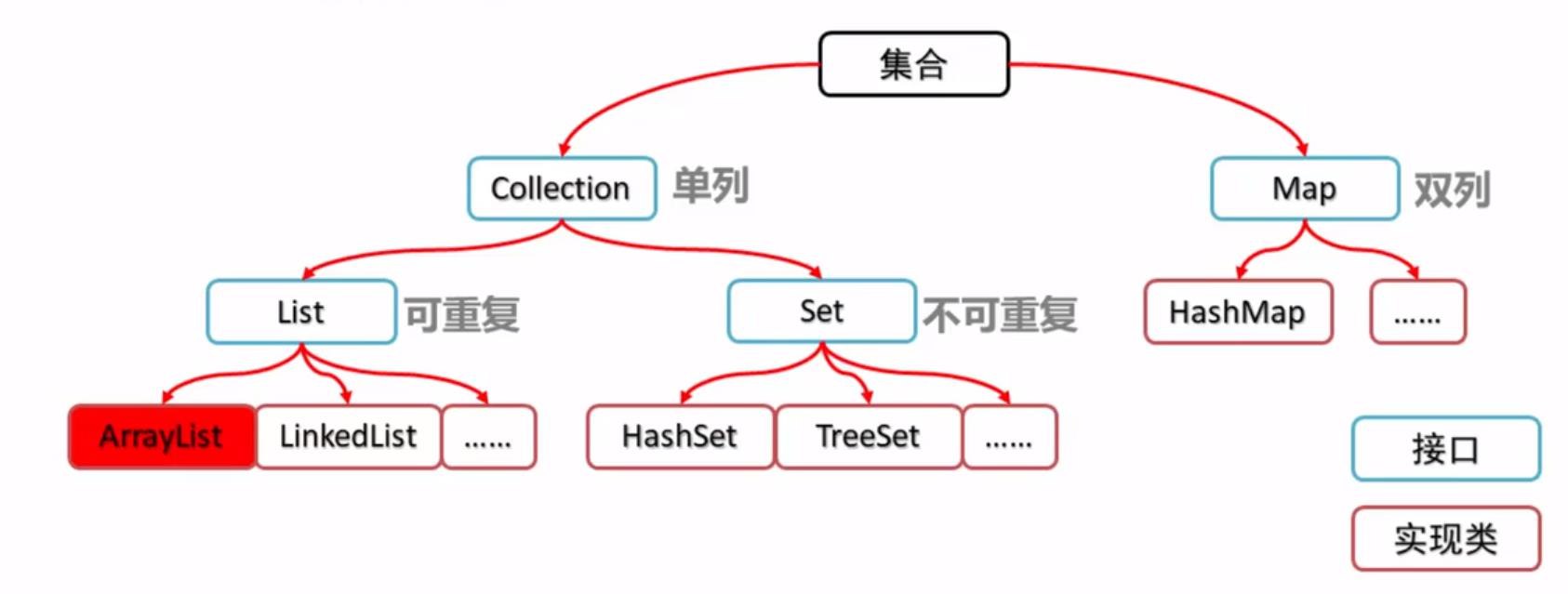
未读1 集合框架图总览我们来简单解读下上面这个框架图:
所有集合类都位于java.util包下
Iterator是遍历集合的工具,我们经常通过Iterator迭代器来遍历集合。我们说Collection依赖于Iterator,是因为Collection的实现类都要实现iterator()函数,返回一个Iterator对象。ListIterator主要作用就是遍历List。
Java的集合类主要由两个接口派生而出:Collection和Map,作为Java集合框架的根接口,这两个接口包含了一些子接口和实现类。
集合接口:即图中的 LinkIterator、List、Set、Queue、SortedMap、SortedMap 6个接口(即短虚线框部分),表示不同集合类型,是集合框架的基础。
抽象类:即图中的 AbstractCollection、AbstractList、AbstractSet、AbstractMap、AbstractSequentialList 5个抽象类(长虚线框部分),抽象类只是对集合接口的部分实现,有需要的话可以继续扩展,完善自定义集合类。
实现类:即图片中LinkH ...

Java核心
未读[TOC]
1 为什么需要多线程我们都知道,CPU、内存、I/O 设备的速度是有极大差异的,为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系结构、操作系统、编译程序都做出了优化,主要体现为:
CPU增加了缓存,均衡了与内存之间的速度差异,但会导致可见性问题
操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异,但会导致原子性问题
编译程序优化指令执行次序,使得缓存能够得到更加合理地利用,但会导致有序性问题
从上面可以看到,虽然多线程平衡了CPU、内存、I/O 设备之间的效率,但是同样也带来了一些问题。
2 线程不安全案例分析如果有多个线程,对一个共享数据进行操作,但没有采取同步的话,那操作结果可能超出预想,产生不一致。
下面举个粒子,设置一个计数器count,我们通过1000个线程同时对它进行增量操作,看看操作之后的值,是不是符合预想中的1000。
123456789101112131415161718192021222324252627282930public class UnsafeThread ...

1 Java内存模型(JMM) 如何解决并发问题维度1:使用关键字、属性进行优化
JMM本质实际就是:Java 内存模型规范了 JVM 如何提供按需禁用缓存和编译优化的方法。这些方法包括了:
volatile、synchronized 和 final 关键字
Happens-Before 规则
维度2:从 顺序一致性、可见性、有序性、原子性角度
顺序一致性
一个线程中的所有操作按照程序的顺序执行,不受其他线程的影响。
原子性
Java程序中,对数据的读和写操作是原子性操作,即这些操作是不可被中断的,要么执行,要么不执行,否则会产生问题。通过下面的案例可以看出,哪些是原子操作,哪些是非原子操作:
12345678// 1个动作,线程直接将值赋给idx,也就是直接写到内存中idx = 100// 3个动作:先定义 jdx,再读取idx的值,最后赋值给jdxjdx := idx// 3个动作:读取jdx的值,进行加1操作,然后新值重新写入新的值jdx ++
从上面的案例中可以看中,只有第一个例子才是具备原子性的,因为他只有一个存的动作。至于其他的例子,包含读取、操作、赋值等多个 ...
Java核心
未读1 先导Java线程基础主要包含如下知识点,相信我们再面试的过程中,经常会遇到类似的提问。
线程有哪几种状态? 线程之间如何转变?
线程有哪几种实现方式? 各优缺点?
线程的基本操作(线程管理机制)有哪些?
线程如何中断?
线程有几种互斥同步方式? 如何选择?
线程之间的协作方式(通信和协调)?
下面我们 一 一 解读。
2 线程的状态和流转
2.1 新建(New)如上图,创建完线程,但尚未启动。
2.2 可运行(Runnable)如上图,处于可运行阶段,正在运行,或者正在等待 CPU 时间片。包含了 Running 和 Ready 两种线程状态。
2.3 阻塞(Blocking)如上图,正被Lock住,等待获取一个排它锁,如果其他的线程释放了锁,该状态就会结束。
2.4 无限期等待(Waiting)如上图,处在无限期等待阶段,等待其它线程显式地唤醒,否则不会被分配 CPU 时间片。主要有两种方式进行释放:
调用方的线程执行完成
使用 Object.notify() / Object.notifyAll()进行显性唤醒
2.5 限期等待(Timed Waiting)如 ...
1 关于消息中间件1.1 什么是消息中间件?消息中间件是指在分布式系统中完成消息的发送和接收的基础软件。消息中间件也可以称消息队列(Message Queue / MQ),用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息队列模型,可以在分布式环境下扩展进程的通信。简而言之,互联网场景中经常使用消息中间件进行消息路由、订阅发布、异步处理等操作,来缓解系统的压力。
1.2 它解决了我们哪些痛点?1、解耦: 比如说系统A会交给系统B去处理一些事情,但是A不想直接跟B有关联,避免耦合太强,就可以通过在A,B中间加入消息队列,A将要任务的事情交给消息队列 ,B订阅消息队列来执行任务。
这种场景很常见,比如A是订单系统,B是库存系统,可以通过消息队列把削减库存的工作交予B系统去处理。如果A系统同时想让B、C、D…多个系统处理问题的时候,这种优势就更加明显了。
2、有序性: 先进先出原理,先来先处理,比如一个系统处理某件事需要很长一段时间,但是在处理这件事情时候,有其他人也发出了请求,可以把请求放在消息队里,一个一个来处理。 ...

1 背景在高并发、高消息吞吐的互联网场景中,我们经常会使用消息队列(Message Queue)作为基础设施,在服务端架构中担当消息中转、消息削峰、事务异步处理 等职能。
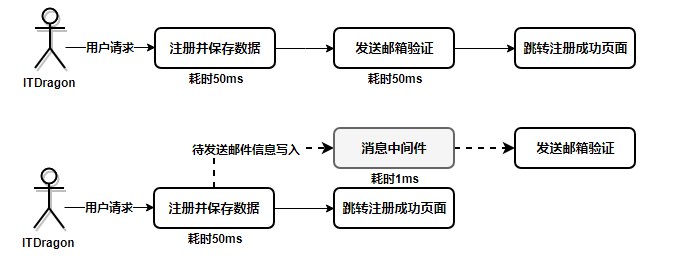
对于那些不需要实时响应的的业务,我们都可以放在消息队列中进行传输。下面是用户在进行系统注册的时候场景,充分体现MQ的作用
可以看到用户注册的过程步骤1+步骤2,从请求到响应总共耗时 55 ms。消息消费+短信发送的时间比较长,从上面看花了5s多,一般让消息队列服务去处理,用户静静等待短信送达即可。
消息队列中间件(简称消息中间件)是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型,它可以在分布式环境下提供应用解耦、
弹性伸缩、冗余存储、流量削峰、异步通信、数据同步等等功能,其作为分布式系统架构中的一个重要组件,有着举足轻重的地位。
2 消息中间件的组成
Broker:消息服务器,以服务的形式运行在server端,给各个业务系统提供核心消息数据的中转服务。
Producer:消息生产者,业务的发起方,负责生产消息传输给broker。
Consu ...

背景今天团队在做线下代码评审的时候,发现同学们在代码中出现了select count(1) 、 select count(*),和具体的select count(字段)的不同写法,本着分析的目的在会议室讨论了起来,那这几种写法究竟孰优孰劣呢,我们一起来看一下。
讨论归纳先来看看MySQL官方对SELECT COUNT的定义:
传送门:https://dev.mysql.com/doc/refman/5.6/en/aggregate-functions.html#function_count
大概可以分下面这几个步骤讨论。
COUNT(expr)的分析COUNT(expr)函数返回的值是由SELECT语句检索的行中expr表达式非null的计数值,一个BIGINT的值。 如果没有匹配到数据,COUNT(expr)将返回0,通常有下面这三种用法:
1、COUNT(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
2、COUNT(*) 则不同,它执行时返回检索到的行数的计数,不管这些行是否包含null值,
3、COUNT(1)跟COUN ...
Redis
未读1 介绍布隆过滤器(Bloom Filter)是 Redis 4.0 版本之后提供的新功能,我们一般将它当做插件加载到 Redis Service服务器中,给 Redis 提供强大的滤重功能。
它是一种概率性数据结构,可用于判断一个元素是否存在于一个集合中。相比较之 Set 集合的去重功能,布隆过滤器空间上能节省90% +,不足之处是去重率大约在 99% 左右,那就是有 1% 左右的误判率,这种误差是由布隆过滤器的自身结构决定的。它有如下优缺点:
优点:空间效率和查询时间都比一般的算法要好的多
缺点:有一定的误识别率和删除困难
详细的原理可以参考笔者的这一篇 《聊聊布隆过滤器(原理) | 数根朽木,》。
2 应用场景说明我们在遇到数据量大的时候,为了去重并避免大批量的重复计算,可以考虑使用 Bloom Filter 进行过滤。具体常用的经典场景如下:
解决大流量下缓存穿透的问题,参考笔者这篇 《生产事故记录-一次雪崩的灾难复盘-转载 | 数根朽木,》。
过滤被屏蔽、拉黑、减少推荐的信息,一般你在浏览抖音或者百度App的时候,看到不喜欢的会设置减少推荐、屏蔽此类信息等,都可以采用这 ...
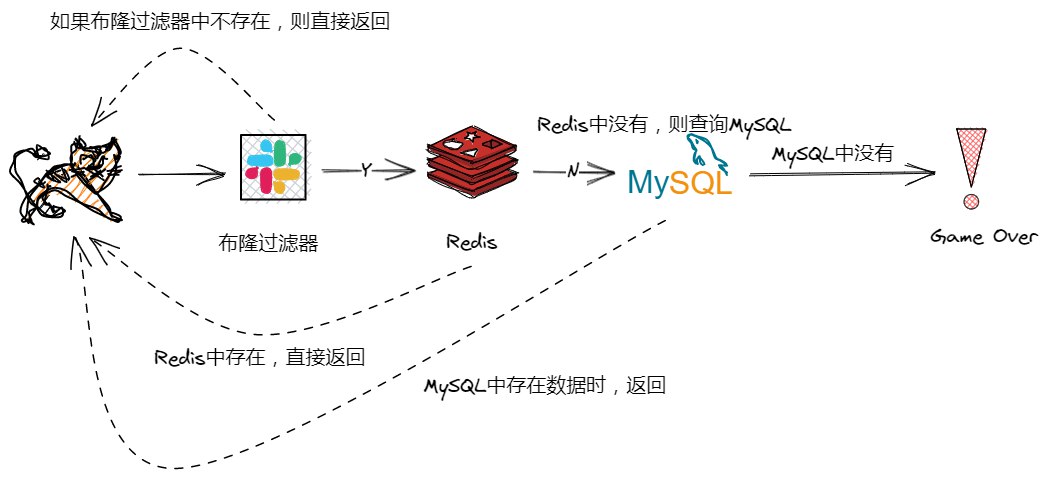
Redis
未读1 Bloom Filter 介绍布隆过滤器(Bloom Filter)是 Redis 4.0 版本提供的新功能,我们一般将它当做插件加载到 Redis 服务器中,给 Redis 提供强大的去重功能。
它是一种概率性数据结构,可用于判断一个元素是否存在于一个集合中。相比较之 Set 集合的去重功能,布隆过滤器空间上能节省 90% +,不足之处是去重率大约在 99% 左右,那就是有 1% 左右的误判率,这种误差是由布隆过滤器的自身结构决定的。
优点:空间效率和查询时间都比一般的算法要好的多
缺点:有一定的误识别率和删除困难
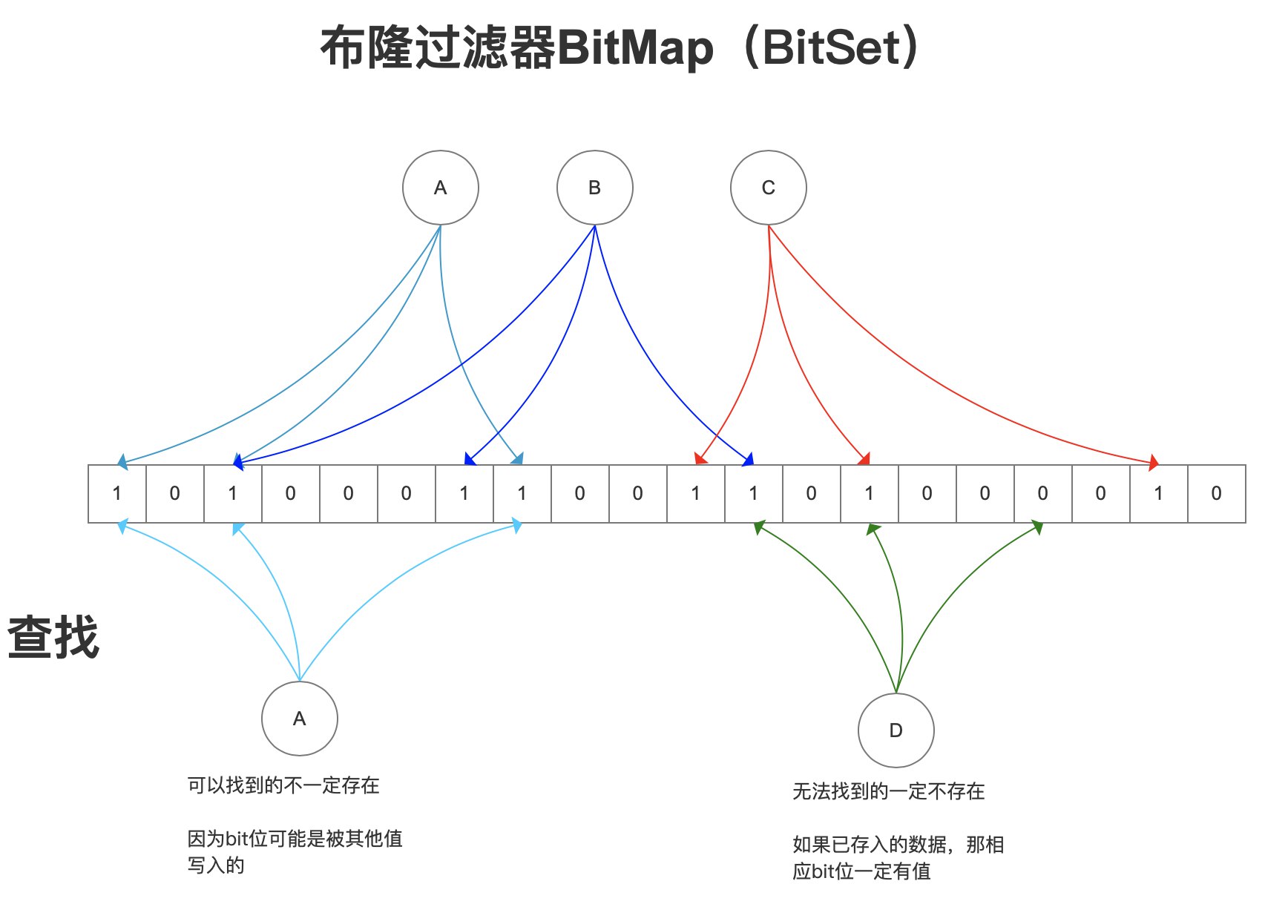
2 原理分析布隆过滤器(Bloom Filter)是一个高空间利用率的概率性数据结构,由二进制向量(即位数组)和一系列随机映射函数(即哈希函数)两部分组成。
通过使用exists()来判断某个元素是否存在于自身结构中。当布隆过滤器判定某个值存在时,其实这个值只是有可能存在;当它说某个值不存在时,那这个值肯定不存在,这个误判概率大约在 1% 左右。原理拆解如下:
在一个很长的二进制向量和一系列随机映射函数的基础上,将元素哈希成不同的位置,每个位置对应二进制向量中的 ...
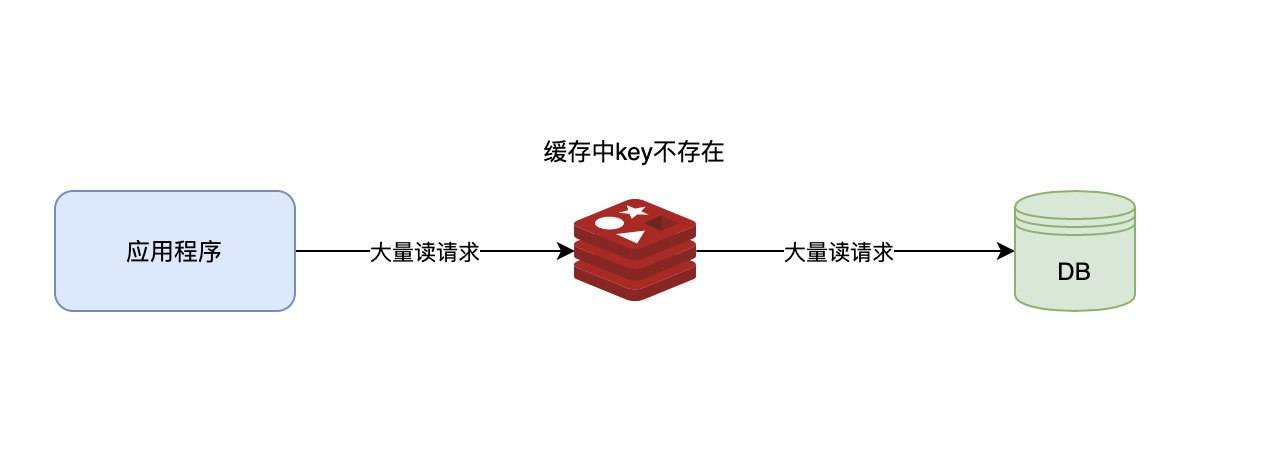
1 真实案例云办公系统用户实时信息查询功能优化发布之后,系统发生宕机事件(系统挂起,页面无法加载)。
1.1 背景我们IM原有的一个功能,当鼠标移动到用户头像的时候,会显示出用户的基本信息。信息比较简单,只包含简单的用户名、昵称、性别、邮箱、电话等基本数据,
这是一个典型的数据查询,大概过程如下左侧,访问用户基本信息的时候会先去Redis中查一下,如果不存在,就把大约2W左右的用户数据一次性取出来,保存在Redis中,因为用户基本信息在同一张表上,用户信息表的数据量也很少,所以一直也没什么问题。
过程如下图左侧所示。
后续对功能做了优化,原有采集的信息除了用户的基本信息之外,还采集了教育经历、工作经历、所获勋章等。
这些信息存储在不同的表里面,所以采集过程是一个复杂的联表查询,特别是有些基础表数据量比较大,执行效率也是比较慢的。
如果把所有用户全部取出来并存储在一个Redis节点中,明显已经不适用,一个是批量查询导致数据库执行效率慢,一个是Redis单节点数据太大。
所以开发同学做了下优化,每次只取单个用户的综合信息存在Redis中,一个用户建一个缓存,如上图右侧所示。
1.2 ...



