
数据库对象命名规范数据库对象数据库对象是数据库的组成部分,常见的有以下几种: 表(Table )、索引(Index)、视图(View)、图表(Diagram)、缺省值(Default)、规则(Rule)、触发器(Trigger)、存储过程(Stored Procedure)、 用户(User)等。 命名规范是指数据库对象如数据库(SCHEMA)、表(TABLE)、索引(INDEX)、约束(CONSTRAINTS)等的命名约定。
数据库对象全局命名规范1、命名使用具有意义的英文词汇,词汇中间以下划线分隔
2、命名只能使用英文字母、数字、下划线,以英文字母开头
3、避免用MySQL的保留字如:backup、call、group等,参考MySQL 5.7+的关键字和保留字。
4、所有数据库对象使用小写字母,实际上MySQL中是可以设置大小写是否敏感的,为了保证统一性,我们这边规范全部小写表示。
数据库命名规范1、数据库命名尽量不超过30个字符。
2、数据库命名一般为项目名称+代表库含义的简写,比如IM项目的工作流数据库,可以是 im_flow。
3、数据库创建时必须添加默认字符集和校对规则子 ...

索引的十大原则1、正确理解和计算索引字段的区分度,文中有计算规则,区分度高的索引,可以快速得定位数据,区分度太低,无法有效的利用索引,可能需要扫描大量数据页,和不使用索引没什么差别。
2、正确理解和计算前缀索引的字段长度,文中有判断规则,合适的长度要保证高的区分度和最恰当的索引存储容量,只有达到最佳状态,才是保证高效率的索引。
3、联合索引注意最左匹配原则:必须按照从左到右的顺序匹配,MySQL会一直向右匹配索引直到遇到范围查询(>、<、between、like)然后停止匹配。
如 depno=1 and empname>’’ and job=1 ,如果建立(depno,empname,job)顺序的索引,job是用不到索引的。
4、应需而取策略,查询记录的时候,不要一上来就使用*,只取需要的数据,可能的话尽量只利用索引覆盖,可以减少回表操作,提升效率。
5、正确判断是否使用联合索引(上面联合索引的使用那一小节有说明判断规则),也可以进一步分析到索引下推(IPC),减少回表操作,提升效率。
6、避免索引失效的原则:禁止对索引字段使用函数、运算符 ...

Redis
未读1 Redis 操作规范1.1 缓存的使用时机判断
【建议】系统为单体系统,整体QPS小于200的,不建议草率引入缓存,应该有更多的办法进行效率提升缓存的引入根据系统的业务流量、应用规模而定,对于系统规模小低并发低流量的应用而言,引入缓存并不会带来性能的显著提升,反而会带来应用的复杂度以及较高的运维成本。
【建议】响应能力,数据响应的正常容忍度为0.5s,临界容忍度为2s,当我们发现响应时间超建议值,并没有太大优化空间的时候,可以考虑加入缓存。说明:建立在对数据具有高效响应的需求的时候,缓存是基于内存映射的,相对于磁盘存取来说会快很多。
【建议】热点数据,这边指的是同一个系统中的相对热点数据,20%的数据占据了整个请求周期(比如24小时)的80%的流量,那就建议在这20%的流量上做缓存。对于热点信息被频繁读取,为避免数据库超载的IO操作的情况下,可以适当使用缓存进行缓冲。
【建议】读写比例,缓存应该建立在多读少写(高频读取、低频修改)的业务场景中。一般读写比要达到 9 : 1,读比例越高越好,这样建立缓存的价值比较大。
1.2 缓存类型的使用建议1.2.1 数据类型1.2.2 字符文 ...

背景某天晚上10点半,下班后愉快的坐在在回家的地铁上,心里想着周末的生活怎么安排。
突然电话响了起来,一看是我们的一个开发同学,顿时紧张了起来,本周的版本已经发布过了,这时候打电话一般来说是线上出问题了。
果然,沟通的情况是线上的一个查询数据的接口被疯狂的失去理智般的调用,这个操作直接导致线上的MySql集群被拖慢了。
好吧,这问题算是严重了,下了地铁匆匆赶到家,开电脑,跟同事把Pinpoint上的慢查询日志捞出来。看到一个很奇怪的查询,如下
1POST domain/v1.0/module/method?order=condition&orderType=desc&offset=1800000&limit=500
domain、module 和 method 都是化名,代表接口的域、模块和实例方法名,后面的offset和limit代表分页操作的偏移量和每页的数量,也就是说该同学是在 翻第(1800000/500+1=3601)页。初步捞了一下日志,发现 有8000多次这样调用。
这太神奇了,而且我们页面上的分页单页数量也不是500,而是 ...
学习如果构建高性能的索引之前,我们先来了解下之前的知识,以下两篇是基础原理,了解之后,对面后续索引构建的原则和优化方法会有更清晰的理解:
MySQL系列:MySQl索引的介绍和原理分析 | 数根朽木,
MySQL系列:MySQl索引的介绍和原理分析 | 数根朽木,
我们编写索引的目的是什么?就是使我们的sql语句执行得更加高效,更快的获取或者处理数据,这个也是建设高性能Web的必要条件。
只有我们深刻理解了索引的原理和执行过程,才能知道怎么恰当地使用索引,以及怎么达到最优的查询。
知识回顾innodb是MySQL默认的存储引擎,使用范围也较广,我们就以innodb存储引擎为例来进行下面方案的说明。
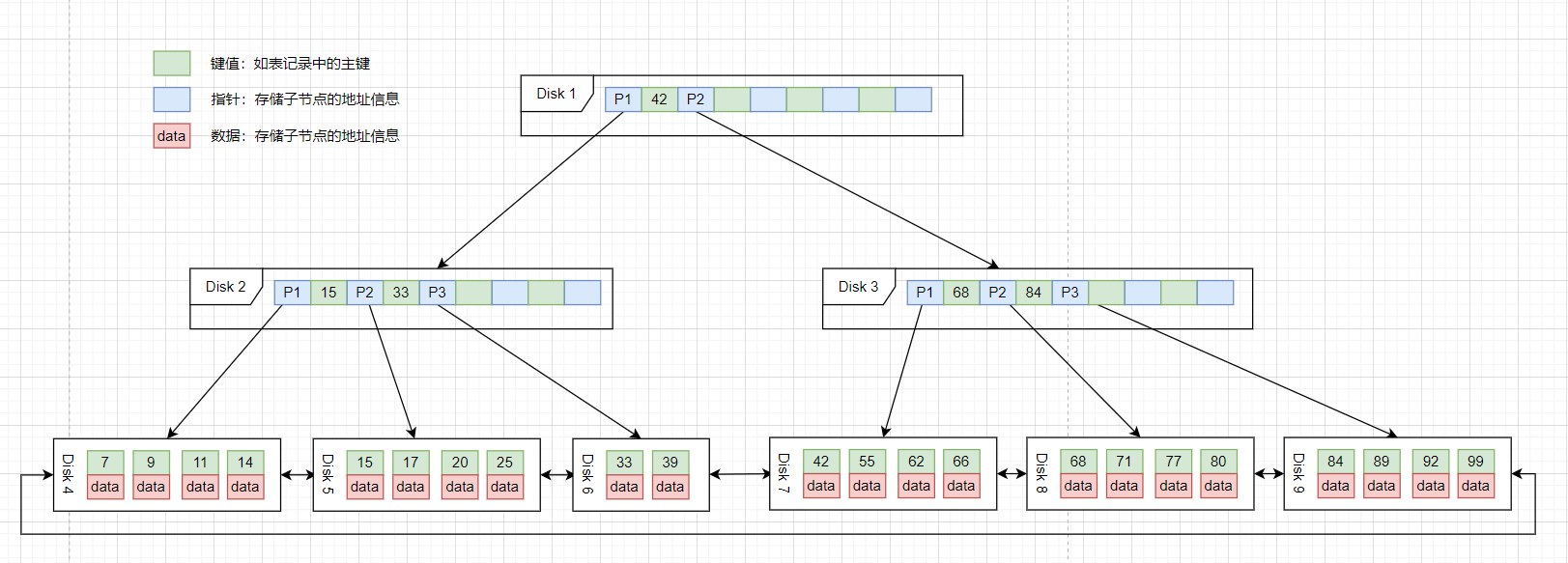
b+树存储结构MySQL采用b+树的方式存储索引信息。b+树图例如下:
b+树结构特点1、叶子节点存储关键字(索引字段的值)信息及对应的值(完整记录)。
2、其他非叶子节点只存储键值信息及子节点的链指针
3、每个叶子节点相当于MySQL中的一页,同层级的叶子节点以双向链表的形式相连
4、每个节点(页)中存储了多条记录,记录之间用单链表的形式连接组成了一条有序的链表,顺序是按照索引字段排序的 ...

MySQL索引实现上一篇我们详细了解了B+树的实现原理(MySQL系列:MySQl索引的介绍和原理分析 | 数根朽木,)。我们知道,MySQL内部索引是由不同的引擎实现的,主要包含InnoDB和MyISAM这两种,并且这两种引擎中的索引都是使用b+树的结构来存储的。
InnoDB引擎中的索引Innodb中有2种索引:主键索引(也叫聚集索引)、辅助索引(也叫非聚集索引)。
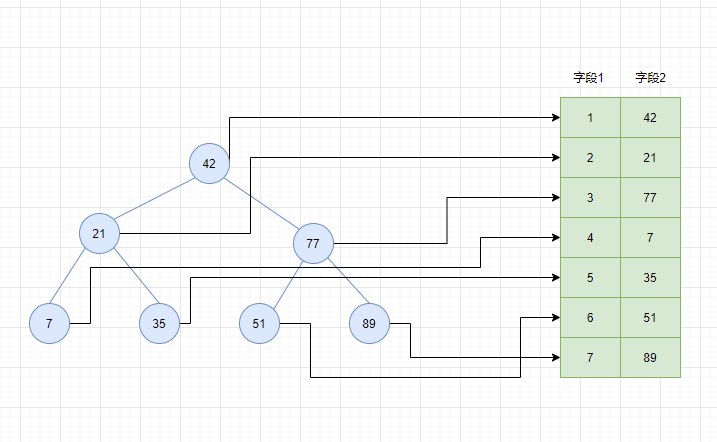
**主键索引:**每个表只有一个主键索引,b+树结构,叶子节点存储主键的值以及对应整条记录的数据,非叶子节点不存储记录的数据,只存储主键的值。
当表中未指定主键时,MySQL内部会自动给每条记录添加一个隐藏的rowid字段(默认4个字节)作为主键,用rowid构建聚集索引。聚集索引在MySQL中即主键索引。
**辅助索引:**每个表可以有多个辅助索引,b+树结构,非聚集索引叶子节点存储字段(索引字段)的值以及对应记录主键的值,其他节点只存储字段的值(索引字段),这就是与聚集索引不同的地方。每个表可以有多个非聚集索引。
MySQL中非聚集索引进一步区分:
非聚集索引类型
说明
单列索引
一个索引只包含一个列 ...
索引的定义MySQL官方对索引的定义为:索引(Index)是协助MySQL高效获取数据的数据结构。
本质上,索引的目的是为了提高查询效率,通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
可以类比银行的保险柜,比如你要找归属你的保险柜子。如果没有索引,你需要拿着钥匙,一个个的保险柜的试过去才能找到属于你的保险柜。但是如果有了索引,而且保险柜能够以物理分区的方式存在在对应的区域,同时你可以根据钥匙上的编号(A1003-10-17),找到保险柜所在 A1003的存放房间,找到存放室保险柜的第10排,再找到第17个位置,找到属于你的保险柜,这个定位就快很多了。在没有索引的情况下,要想完成这个事情还是比较困难的。
索引的原理除了保险柜之外,生活中可以引出很多类似的索引例子,如字典词典的目录、图书馆的检索录、火车的座次表等。
它们的原理一致:不断的缩小数据范围来筛选数据,并把随机数据变成顺序数据,方便我们更快地锁定数据。
这种索引的理解同样适用我们的数据库查询,但是数据库会有很多更复杂的 ...
Java核心
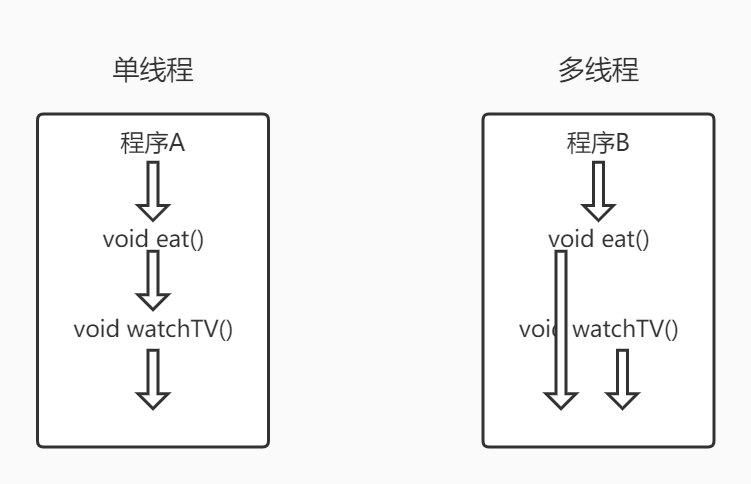
未读1 线程的基本概念线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。每个线程都有一个独立的执行路径,但共享进程的资源,如内存和文件句柄。在Java中,线程可以通过继承Thread类或实现Runnable接口来创建。
此外,Java 5开始,引入了java.util.concurrent包,提供了更多的并发工具,如Callable接口与Future接口,它们主要用于任务执行。
2 线程的创建与启动2.1 继承Thread类
创建一个类继承自Thread类。
重写run()方法,该方法包含了线程要执行的任务。
创建该类的对象,并调用start()方法启动线程。
123456789101112class MyThread extends Thread { public void run() { System.out.println("线程运行中"); }}public class ThreadDemo { public static void main( ...

Java核心
未读1 介绍无论是那种语言体系,反射都是必不可少的一个技术特征。从Java体系来说,很多常用的技术框架或多或少都使用到了反射技术,比如Spring、MyBatis、RocketMQ、FastJson 等等。反射技术强大而必要,在大多数框架中起到举足轻重的作用。所以,反射也是Java必不可少的核心技术之一。
接下来我们来看看反射的一些技术要点:
反射的概念(即什么是反射)?
反射的作用(它帮我们解决了哪些问题)?
反射的实现原理?
如何使用反射?下面我就针对以上的疑问,一一来讲解。
1.1 反射是什么?Java反射(Reflection)是Java语言的一个核心特性,它允许运行中的Java代码对自身进行自我检查,甚至修改自身的组件。具体来说,反射机制提供了在运行状态中,对于任意一个类,都能够了解这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性。这种动态获取的信息以及动态调用对象的方法在Java中就叫做反射。
一句话总结:反射就是在运行时才具体知晓要操作的类是什么结构,并在运行时获取类的完整构造,并调用对应的方法、属性等。
Java的反射主要包括以下三个部分:
...
Java核心
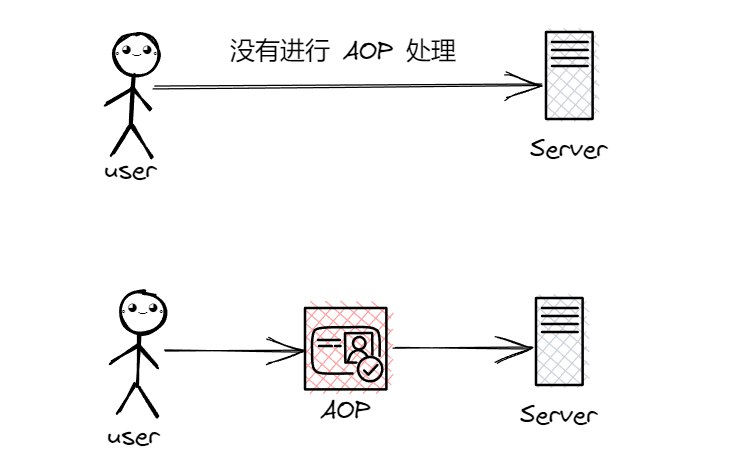
未读1 概述我们所说的Aop(即面向切面编程),即面向接口,也面向方法,在基于IOC的基础上实现。
Aop最大的特点是对指定的方法进行拦截并增强,这种增强的方式不需要业务代码进行调整,无需侵入到业务代码中,使业务与非业务处理逻辑分离。
以Spring举例,通过事务的注解配置,Spring会自动在业务方法中开启、提交业务,并且在业务处理失败时,执行相应的回滚策略。
aop的实现主要包括了两个部分:
匹配符合条件的方法(Pointcut)
对匹配的方法增强(JDK代理、cglib代理)spring针对xml配置和配置自动代理的Advisor有很大的处理差别,在IOC中主要是基于XML配置分析的,在AOP的源码解读中,则主要从自动代理的方式解析,分析完注解的方式,再分析基于xml的方式。
2 案例分析下面是spring aop的用法,也是用于源码分析的案例切面类:TracesRecordAdvisor
1234567891011121314151617181920@Aspect@Componentpublic class TracesRecordAdvisor { @ ...



